Beam College past sessions
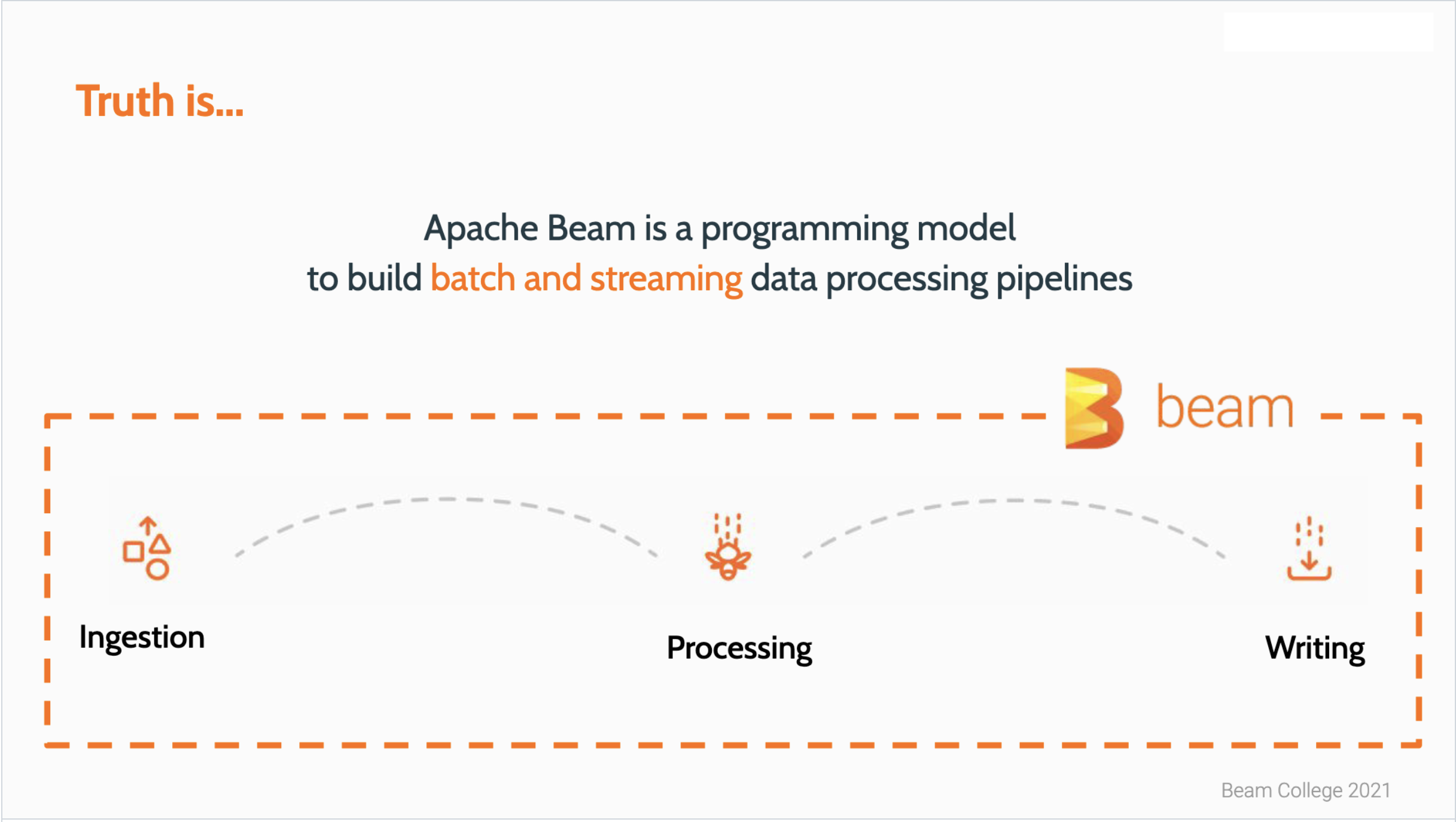

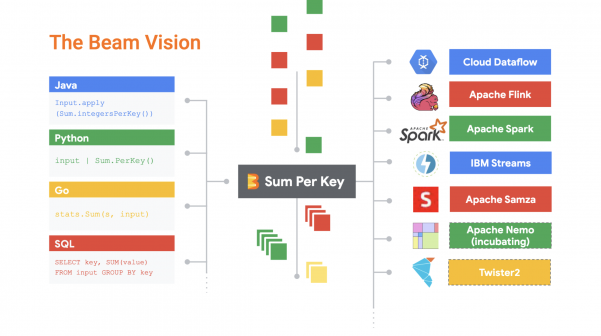
Basic explanation of what is Apache Beam, what is the problem that it tries to solve and how it relates to other tools in the ecosystem like Spark and Flink.
Miren Esnaola explains the basic concepts behind Apache Beam and data processing “the Beam way”.
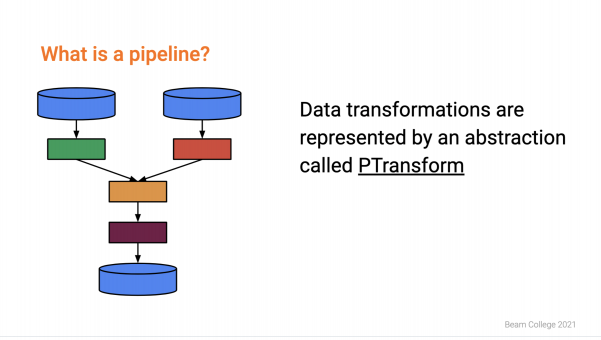
- What is a PCollection?
- What is a PTransform?
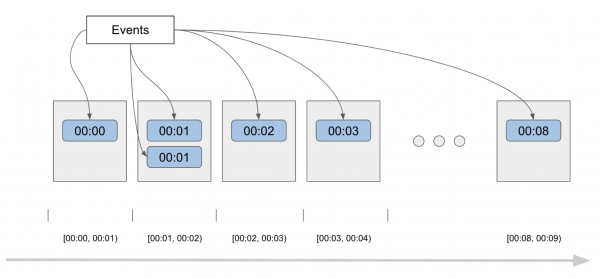
- Understanding time in Beam (event time vs processing time).
Tyson Hamilton explains how a data pipeline is declared in Apache Beam with DAGs.
Harsh Vardhan provides a high level overview of what is a runner in Apache Beam, their architecture, management and typical features.
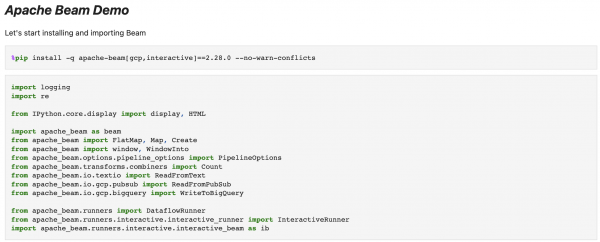
Iñigo San José demos some of the main capabilities of Apache Beam using a notebook in Google Colab together with Dataflow.
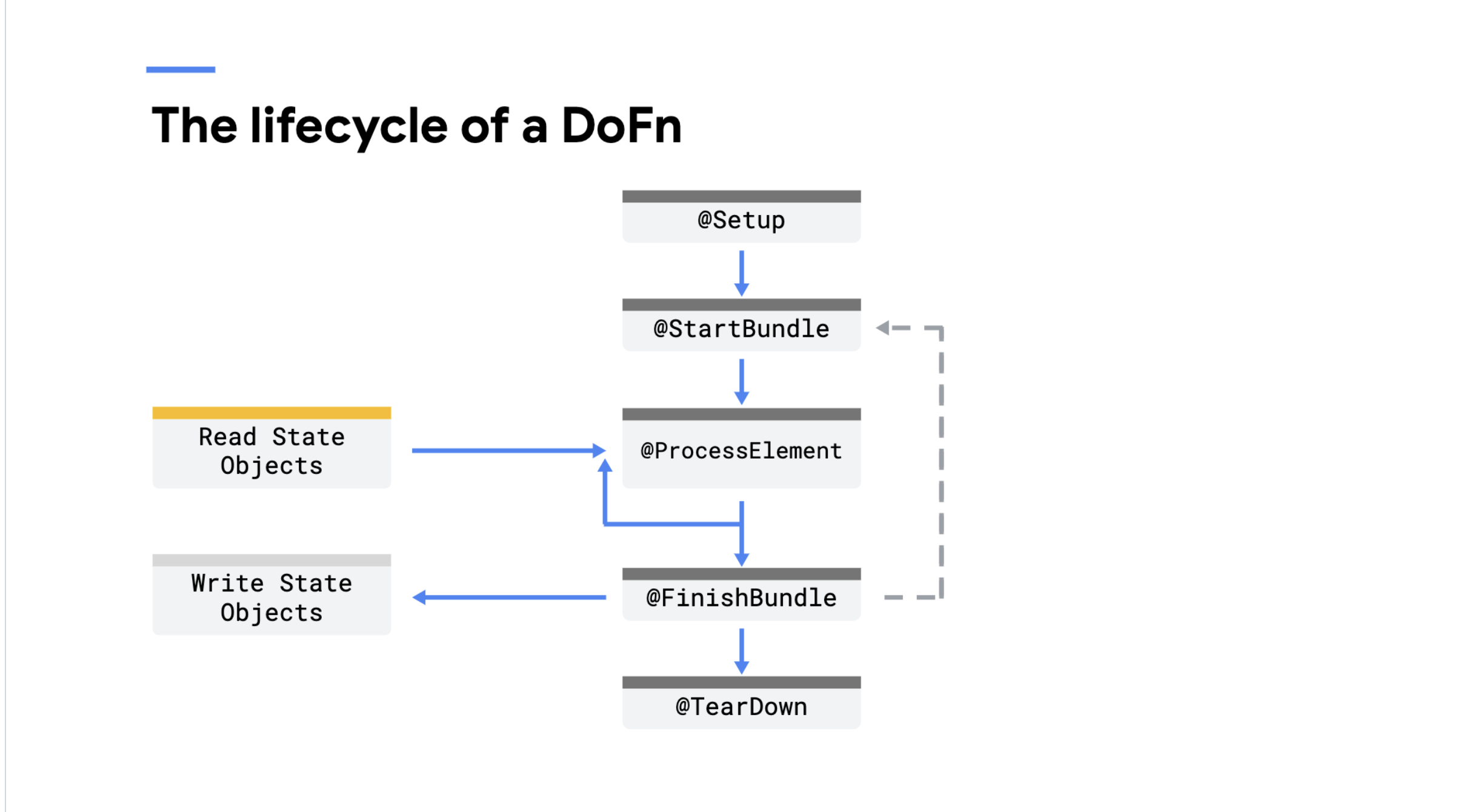
Israel Herraiz explains the lifecycle and possibilities of ParDo and DoFn, which are central to how Beam processes data in parallel.
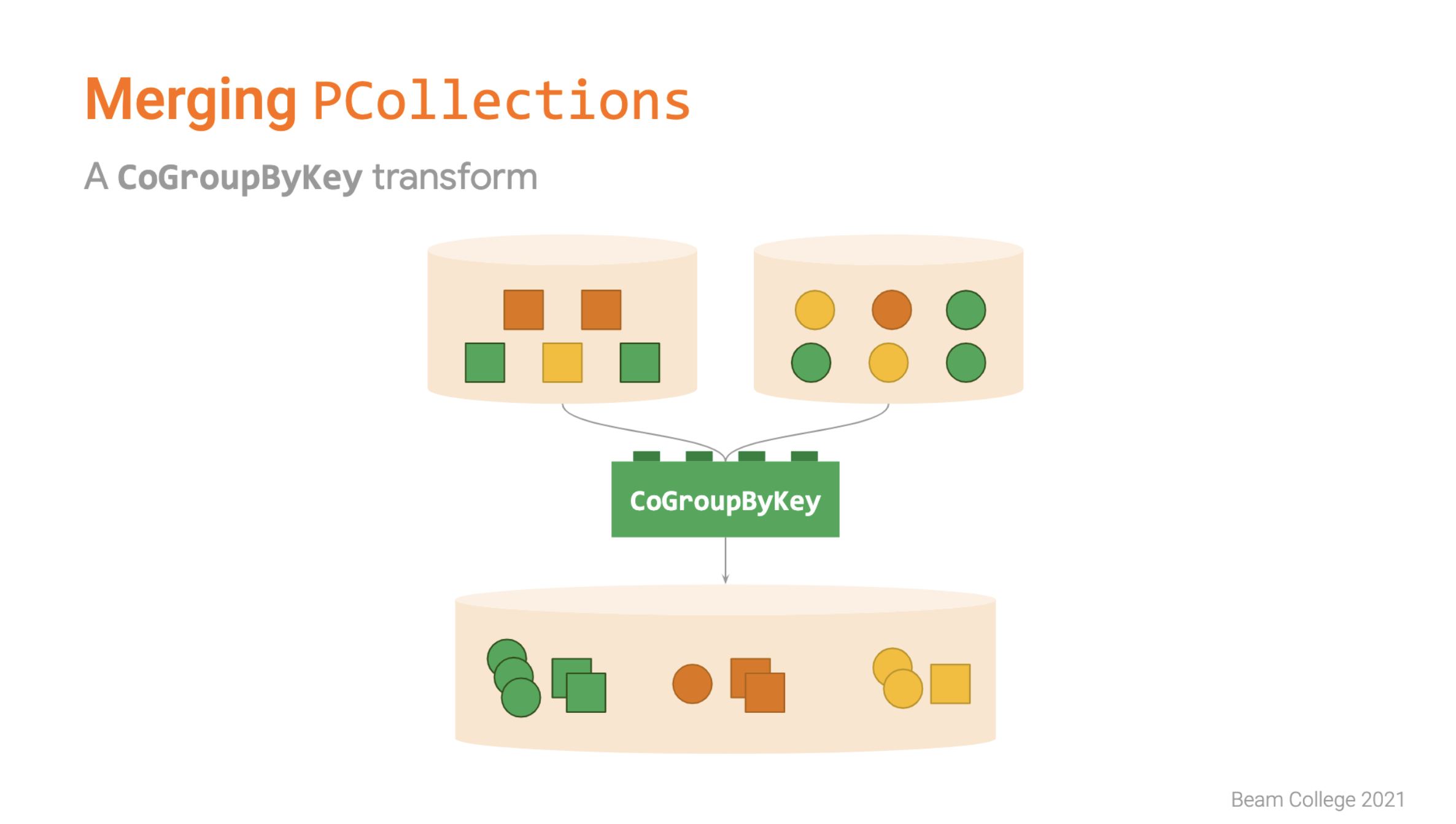
In this session Miren and Iñigo explain two very common patterns that are used for defining pipelines in Apache Beam: Branching and Merging.
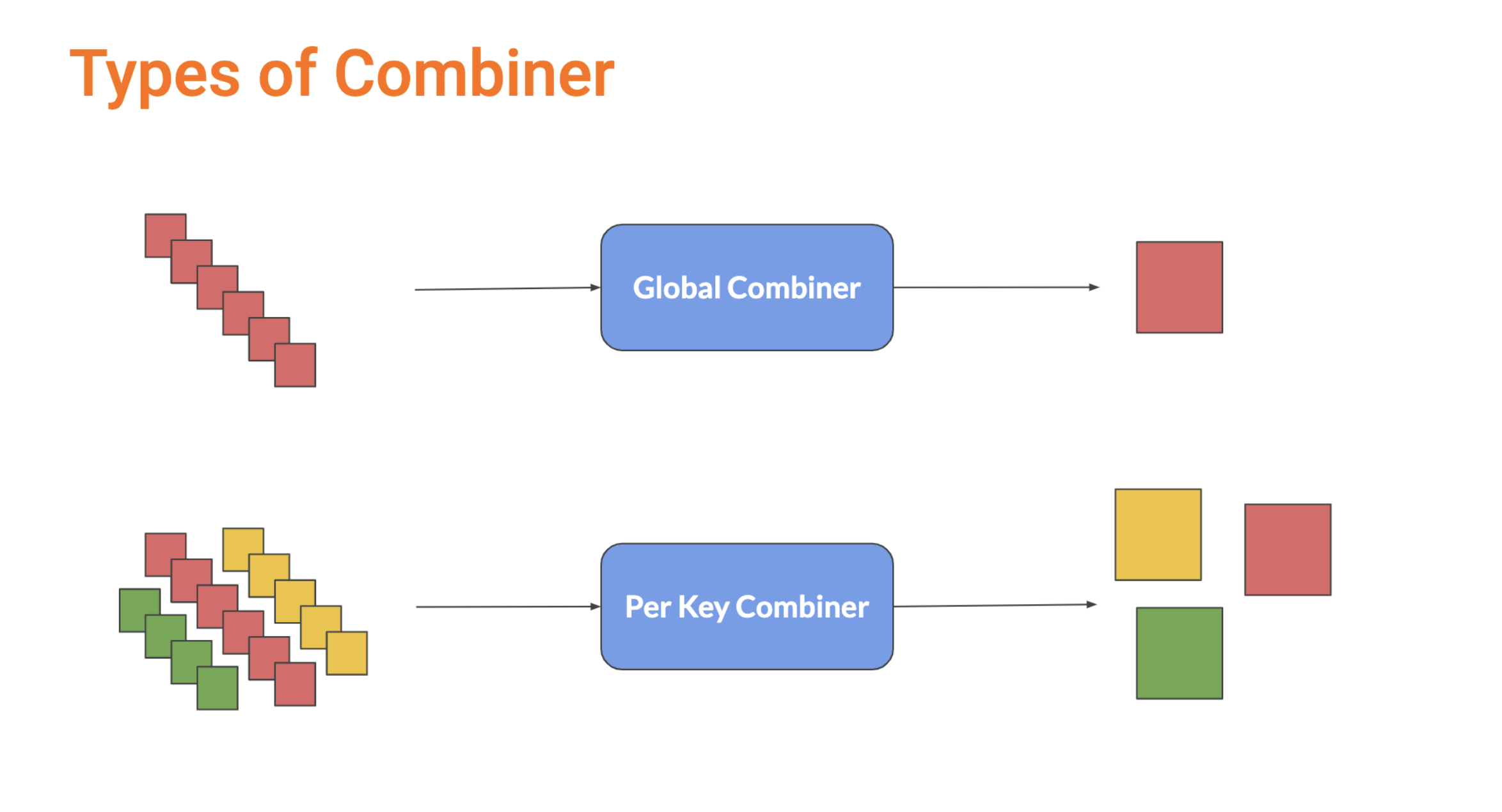
Iñigo explains Combiners, which are basically transformations (PTransforms) that combine multiple collections (PCollections) of data into a single PCollection.
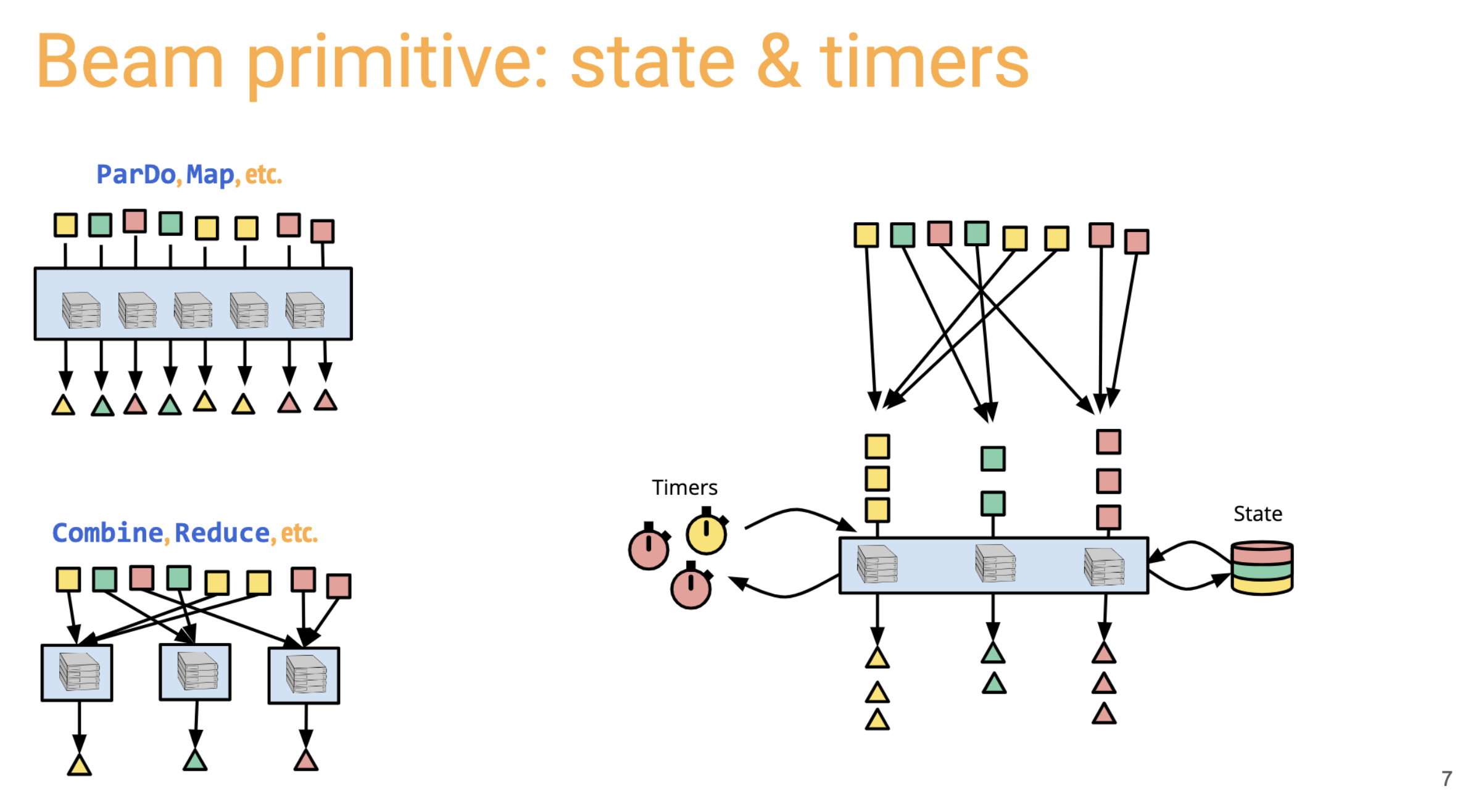
Ken Knowles explains the fine details of how to manage time and state in Apache Beam.
Reza Rokni & Ahmet Altay provide a demo that explains the use of windows and triggers in Apache Beam.
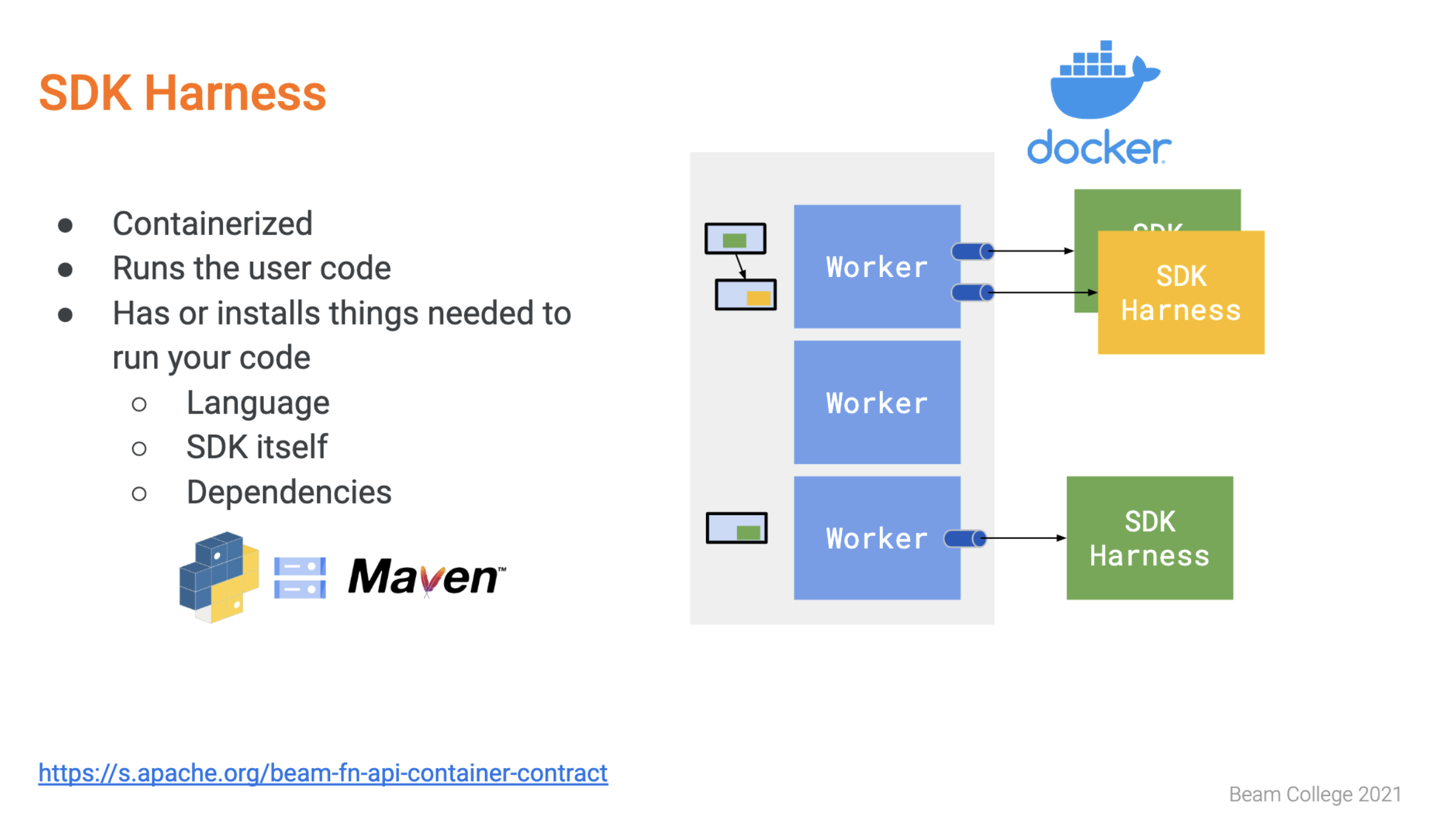
Emily Ye shares best practices for creating custom container images for porting Apache Beam pipelines to different runners.